Capítulo 5 Fatorial 2k com pontos centrais
5.1 Fundamentação
No capítulos anteriores discutiu-se os experimentos fatoriais \(2^k\) com e repetições e sem repetições dos pontos experimentais. Essencialmente, a análise desses experimentos baseou-se um modelo na qual o efeito dos fatores é linear na resposta. Por mais que termos de interação sejam declarados, ainda assim, o efeito é linear. Ou seja, o efeito de um dado fator é linear fixando-se o níveis das demais fatores.
No entanto, na prática não tem-se garantia alguma de que a resposta seja uma função linear dos fatores. A verdadeira função é desconhecida. E o fato de usar apenas dois níveis para cada fator não permite que modelos mais complexos sejam ajustados. A preocupação que surge é: se a função não for linear nessa região experimental, as inferências feitas a partir do modelo linear que foi assumido são equivocadas. A questão é: como diagnosticar, sem aumentar o custo do experimento, se a suposição de linearidade é válida? Além disso, qual as implicações resultantes dessa hipóptese ser negada? Como o experimentador desse proceder?
No experimento fatorial com replicação tem-se uma estimativa pura do erro experimental. Mas não há mecanísmos para diagnosticar se a suposição de linearidade da resposta em relação aos fatores é apropriada na região experimental estudada. No experimental fatorial sem repetições não possui-se uma estimativa pura da variância do erro experimental. Uma estimativa é conseguida com o abandono de termos de maior ordem cujos efeitos são examinados pelo gráfico quantil quantil normal. No entanto, pode-se cometer erros ao abandonar termos relevantes. Além do mais, também não é possível diagnosticar falta de ajuste devido à inadequação do modelo de efeitos lineares.
A solução para os problemas indicados é muito simples. É adicionar pontos centrais. Os pontos centrais são corridas experimentais feitas nas coordenadas 0, ou seja, na origem considerando a escala codificada dos fatores. As vantagens e desvantagens do emprego de pontos centrais são discutidas na sequência: 1. Os pontos centrais permitem obter uma estimativa pura da variância residual. Ela é construida a partir dos desvios das repetições em relação a média do ponto central, ou seja, \[ \sigma^2_\text{pura} = \sum_i^{r_{pc}} (y_{pc(i)} - \bar{y}_{pc})^2/(r_{pc} - 1) \] 2. Eles permitem testar a hipótese nula de curvatura zero ou, equivalentemente, indicar a presença de falta de ajuste para o modelo de efeitos lineares. Isso quer dizer que, baseado na diferença entre o valor predito para o ponto experimental e o valor observado, pode-se testar se há desvio da hipótese de relação linear da resposta com os fatores dentro da região experimental. É um teste baseado em um grau de liberdade. 3. Não é possível ter pontos centrais em todas os fatores quando algum deles é qualitativo já que o ponto 0 representa um nível intermediário entre os níveis -1 e 1. 4. Embora seja possível detectar a presença de curvatura da função, apenas com os pontos fatoriais e centrais não é possível ajustar um modelo com termos para acomodar a curvatura e predizer a resposta. É necessário, portanto, que o delineamento tenha valores observados em novos pontos dentro da região experimental.
O modelo considerado para o experimento fatorial \(2^k\) com \(r_{pc}\) pontos adicionais tem um termo a mais. Usando o fatorial \(2^2\), o modelo é \[ \text{E}(y) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_{12} x_1 x_2 + \delta \]
em que \(\beta_1\) e \(\beta_2\) e acomodam o efeito do primeiro e segundo fatores, \(\beta_{12}\) acomoda a interação entre eles e \(\delta\) é o parâmetro que representa a discrepância entre o valor esperado no ponto central, \(f(x_1 = 0, x_2 = 0) = \beta_0\), e o valor esperado da resposta no ponto central, \(\text{E}(y_{pc})\). Portanto, \(\delta = \text{E}(y_{pc}) - \beta_0\).
Para obter uma estimativa do parâmetro de falta de ajuste, precisa-se apenas criar um variável indicadora que vale 1 quando o ponto é central e 0 quando o ponto e fatorial. A diferença entre médias amostrais é a estimativa de \(\delta\), \[ \hat{\delta} = \bar{y}_{pc} - \bar{y}_{pf}. \]
A soma de quadrados é dada por \[ SQ_\delta = \frac{(r_{pc} \cdot r2^k) \cdot \hat{\delta}^2}{r_{pc} + r2^k}. \]
A hipótese testada com a inclusão do parâmetro \(\delta\) é \[ H_0: \delta = 0 \Rightarrow \beta_{ii} = 0 \text{ para todo } i = 1,\ldots, k, \] no modelo \[ \text{E}(y) = \beta_0 + \sum_i \beta_i x_i + \underset{\text{interações duplas}}{ \sum_{i < j} \beta_{ij} x_i x_j} + \underset{\text{curvaturas}}{ \sum_i \beta_{ii} x_i^2}. \] Por simplicidade, indicou-se apenas as interações duplas mas o modelo deve conter as interações até ordem \(k\).
Embora não seja possível ajustar o modelo acima aos dados do experimento fatorial \(2^k\) com pontos centrais, os pontos centrais permitem incluir o parâmetro \(\delta\) testar se a curvatura é nula. A inclusão de pontos centrais tem baixo custo e fornece o benefício adicional de fornecer uma estimativa pura da variância residual.
No caso da hipótese não ser rejeitada, procede-se a análise com o modelo linear no efeito dos fatores. A partir dele, direções para regiões experimentais mais promissoras podem ser determinadas. No caso da hipótese ser rejeitada, significa que a presença de curvatura foi detectada. Isso quer dizer que o ponto estacionário (máximo, mínimo ou cela) esteja próximo da atual região experimental. Nessa situação, o atual experimento pode ser enriquecido com pontos de experimentais adicionais que permitam ajustar um modelo com termos quadráticos, por exemplo.

Figura 5.1: Experimento fatorial \(2^2\) com 5 pontos adicionais. Os valores anotados correspondem a resposta medida em cada condição experimental. Os dados fazem serão analizados na próxima seção.

Figura 5.2: Experimento fatorial \(2^2\) com ponto central. A figura ilustra que a discrepância entre a média amostral no ponto central \(\bar{y}_{pc}\) é o valor ajustado no ponto central \(\hat{y}\) indica o tamanho da falta de ajuste (LOF: lack of fit).

Figura 5.3: Ações em relação a rejeição da hipótese sobre a curvatura na região experimental.
library(lattice)
library(tidyverse)5.2 Rendimento de um processo químico
Um engenheiro químico está estudando a conversão percentual ou o rendimento de um processo. Há duas variáveis de interesse: o tempo e a temperatura de reação. Pelo fato de não ter certeza em relação à linearidade da região de exploração, o engenheiro decide conduzir um planejamento \(2^2\) com uma única réplica dos pontos experimentais aumentado com 5 pontos centrais. O planejamento com os dados de rendimento são mostrados na Figura 5.1.
Esses dados são do exemplo 14-6, na página 353 do MONTGOMERY; RUNGER (2009). Os mesmos estão na página 273, seção 6-6 do MONTGOMERY (2001).
O fragmento abaixo cria os dados no ambiente R e faz gráficos para inspeção dos mesmos.
# Construção dados dados.
da <- rbind(expand.grid(tem_reac = c(30, 40),
temper = c(150, 160),
lof = 0,
KEEP.OUT.ATTRS = FALSE),
list(rep(35, 5),
rep(155, 5),
rep(1, 5)))
da$rend <- c(393, 409, 400, 415,
406, 402, 407, 405, 403)/10
gg1 <-
ggplot(data = da,
mapping = aes(x = tem_reac, y = rend, color = factor(temper))) +
geom_point() +
stat_summary(mapping = aes(group = 1),
color = 1,
geom = "line",
fun.y = "mean")
gg2 <-
ggplot(data = da,
mapping = aes(x = temper, y = rend, color = factor(tem_reac))) +
geom_point() +
stat_summary(mapping = aes(group = 1),
color = 1,
geom = "line",
fun.y = "mean")
gridExtra::grid.arrange(gg1, gg2, ncol = 1)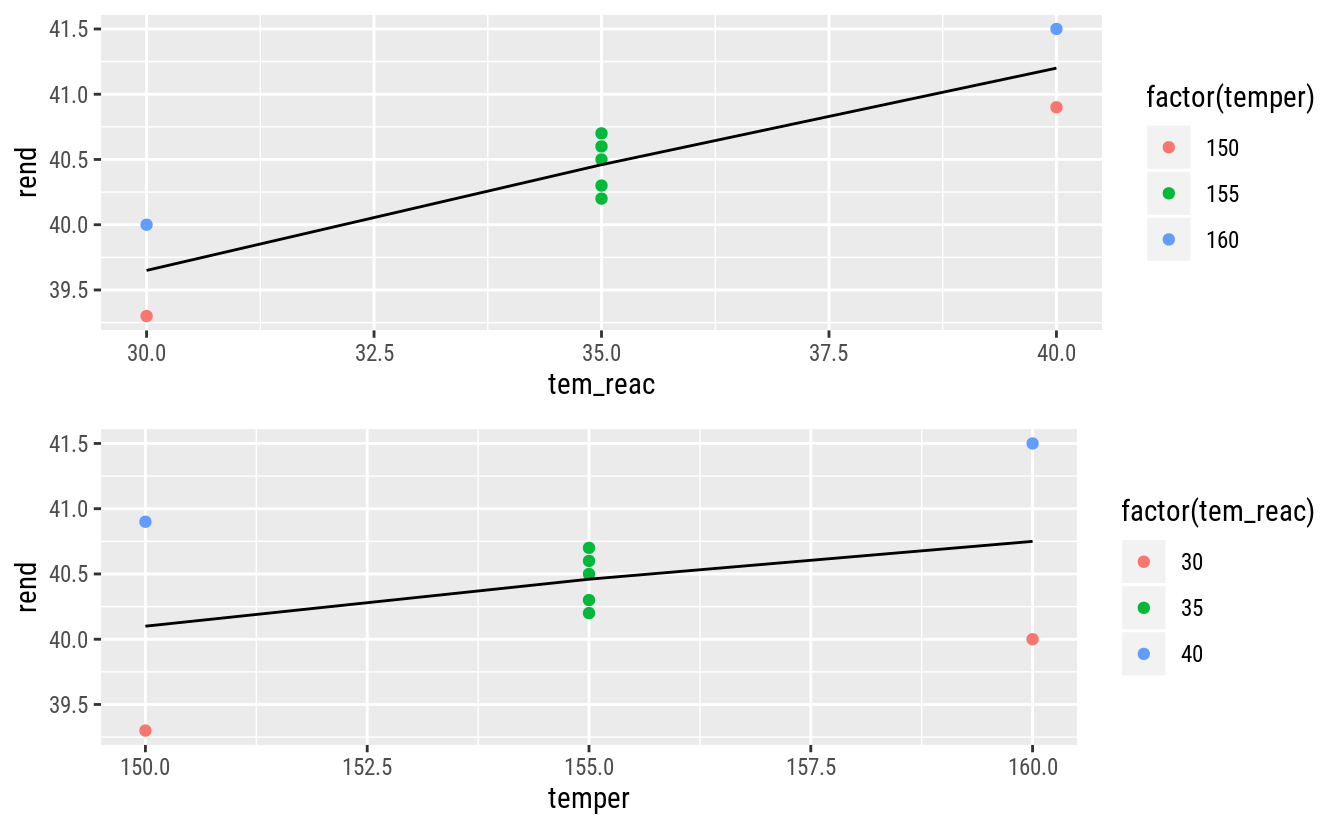
Os gráficos não fornecem evidências para a rejeição da hipótese de que o modelo linear nas variáveis é adequado para modelar a média da resposta nessa região experimental. A média amostral nos pontos centrais é muito próxima à média predita para o ponto central.
A função codify() foi criada para converter para a escala codificada as os fatores experimentais que estão na escala natural.
# Para codificar as variáveis.
codify <- function(x, extremes = range(x)) {
r <- extremes
m <- mean(r)
s <- 0.5 * diff(r)
(x - m)/s
}
da$A <- codify(da$tem_reac)
da$B <- codify(da$temper)No fragmento abaixo é feito o ajuste do modelo aos dados. A variável lof é uma variável indicadora onde o valor 1 corresponde aos pontos centrais e o valor 0 aos pontos fatoriais. Dessa forma, o parâmetro associado a essa variável é interpretado como diferença entre a média amostral das repetições do ponto central (\(\bar{y}_{pc}\)) e a média predita para o ponto central (\(\hat{y}_{pc}\)). Quando maior essa diferença, maior é a evidência contra a suposição de curvatura nula, ou, de forrma equivalente, a suposição de que o modelo linear nos fatores é adequado.
# Ajuste do modelo com pontos centrais.
m0 <- lm(terms(rend ~ A * B + lof, keep.order = TRUE),
data = da)
anova(m0)## Analysis of Variance Table
##
## Response: rend
## Df Sum Sq Mean Sq F value Pr(>F)
## A 1 2.40250 2.40250 55.8721 0.001713 **
## B 1 0.42250 0.42250 9.8256 0.035030 *
## A:B 1 0.00250 0.00250 0.0581 0.821316
## lof 1 0.00272 0.00272 0.0633 0.813741
## Residuals 4 0.17200 0.04300
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1O quadro de análise de variância indica, pelos valores do termo lof, não haver evidências de curvatura diferente de 0.
A estimativa pura da variância do erro é, no caso de um experimento com repetições apenas para o ponto central, a variância amostral das observações no ponto central. A estimativa do parâmetro associado a variável lof, bem como a corresponde soma de quadrados, é fácil de obter. O código abaixo faz as contas indicadas.
# Estimativa pura da variância do erro.
anova(m0)["Residuals", "Mean Sq"]## [1] 0.043s2 <- var(da$rend[da$lof == 1])
s2## [1] 0.043# Médias dos pontos fatoriais e centrais.
m <- with(da, tapply(rend, lof, mean))
# Diferença entre as médias é o termo de falta de ajuste.
c(m, diff = unname(diff(m)))## 0 1 diff
## 40.425 40.460 0.035coef(m0)["lof"]## lof
## 0.035# Soma de quadrados de `lof`.
n <- with(da, tapply(lof, lof, length))
sq_lof <- prod(n) * coef(m0)["lof"]^2/sum(n)
sq_lof## lof
## 0.002722222# Estatística F do quadro de anova.
sq_lof/s2## lof
## 0.063307495.3 Fabricação de semicondutores
A planilha eletrônica com os dados usados em MONTGOMERY (2012) está disponível para download no endereço http://bcs.wiley.com/he-bcs/Books?action=resource&bcsId=7009&itemId=1118146921&resourceId=26715&chapterId=75851. Os dados no fragmento de código abaixo estão na guia “Chapter 06” com nome “Problem 23” pois correspondem ao exercício 6-23.
Os processos de fabricação de semicondutores têm fluxos de montagem longos e complexos. Portanto, marcas de matriz e leitores automatizados de matriz 2D são usados em várias etapas do processo nas fábricas. Marcas de matriz ilegíveis afetam negativamente as taxas de operação de fábrica porque é necessária a entrada manual de dados da peça antes que a fabricação possa retomar. Um experimento fatorial \(2^4\) foi conduzido para desenvolver uma marca de laser de matriz 2D em uma cobertura de metal que protege uma matriz montada em substrato. Os fatores de design são potência do laser (A: 9 e 13 W), frequência de pulso do laser (B: 4000 e 12000 Hz), tamanho da célula da matriz (C: 0,07 e 0,12 polegadas) e velocidade de gravação (D: 10 e 20 polegadas/segundo). A variável de resposta é a correção de erro não utilizada (UEC). O experimento teve ainda a adição de pontos centrais para compor uma estimativa pura do erro experimental e permitir diagnosticar falta de ajuste. Um UEC de 0 representa a leitura mais baixa que ainda resulta em uma matriz decodificável, enquanto um valor de 1 é a leitura mais alta.
O fragmento abaixo cria o objeto no R com os dados do experimento. Gráficos são feitos para inspeção dos dados.
txt <- "Laser Power Pulse Frequency Cell Size Writing Speed UEC
-1 -1 -1 -1 0,75
1 -1 -1 -1 0,98
-1 1 -1 -1 0,72
1 1 -1 -1 0,98
-1 -1 1 -1 0,63
1 -1 1 -1 0,67
-1 1 1 -1 0,65
1 1 1 -1 0,8
-1 -1 -1 1 0,6
1 -1 -1 1 0,81
-1 1 -1 1 0,63
1 1 -1 1 0,79
-1 -1 1 1 0,56
1 -1 1 1 0,65
-1 1 1 1 0,55
1 1 1 1 0,69
0 0 0 0 0,98
0 0 0 0 0,95
0 0 0 0 0,93
0 0 0 0 0,96"
da <- read.table(textConnection(txt),
header = TRUE, sep = "\t", dec = ",")
str(da)## 'data.frame': 20 obs. of 5 variables:
## $ Laser.Power : int -1 1 -1 1 -1 1 -1 1 -1 1 ...
## $ Pulse.Frequency: int -1 -1 1 1 -1 -1 1 1 -1 -1 ...
## $ Cell.Size : int -1 -1 -1 -1 1 1 1 1 -1 -1 ...
## $ Writing.Speed : int -1 -1 -1 -1 -1 -1 -1 -1 1 1 ...
## $ UEC : num 0.75 0.98 0.72 0.98 0.63 0.67 0.65 0.8 0.6 0.81 ...da %>%
gather("fator", "valor", 1:4) %>%
ggplot(mapping = aes(x = valor, y = UEC)) +
facet_wrap(facets = ~fator) +
geom_point() +
stat_summary(mapping = aes(group = 1),
color = 1,
geom = "line",
fun.y = "mean")
names(da) <- c(LETTERS[1:4], "y")
da$lof <- as.integer(da$A == 0)Os gráficos fornecem evidência de que a hipótese de curvatura nula seja falsa. A média amostral no ponto central não encontra-se na posição correspondente a um efeito linear dos fatores na resposta, ou seja, no ponto médio entre as médias marginais dos pontos fatoriais.
O código abaixo declara o modelo e exibe o quadro de análise de variância.
# Ajuste do modelo com pontos centrais.
m0 <- lm(y ~ A * B * C * D + lof,
data = da)
anova(m0)## Analysis of Variance Table
##
## Response: y
## Df Sum Sq Mean Sq F value Pr(>F)
## A 1 0.102400 0.102400 236.3077 0.0005980 ***
## B 1 0.001600 0.001600 3.6923 0.1504103
## C 1 0.070225 0.070225 162.0577 0.0010457 **
## D 1 0.050625 0.050625 116.8269 0.0016941 **
## lof 1 0.182405 0.182405 420.9346 0.0002532 ***
## A:B 1 0.001225 0.001225 2.8269 0.1912867
## A:C 1 0.012100 0.012100 27.9231 0.0132187 *
## B:C 1 0.002500 0.002500 5.7692 0.0957089 .
## A:D 1 0.000400 0.000400 0.9231 0.4075444
## B:D 1 0.000400 0.000400 0.9231 0.4075444
## C:D 1 0.005625 0.005625 12.9808 0.0366874 *
## A:B:C 1 0.002025 0.002025 4.6731 0.1193811
## A:B:D 1 0.001225 0.001225 2.8269 0.1912867
## A:C:D 1 0.001600 0.001600 3.6923 0.1504103
## B:C:D 1 0.001600 0.001600 3.6923 0.1504103
## A:B:C:D 1 0.000025 0.000025 0.0577 0.8256586
## Residuals 3 0.001300 0.000433
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Pelo quadro de análise de variância verifica-se que a hipótese de curvatura nula é rejeitada (à 1%). Dessa forma, suspeita-se que o ótimo da resposta esteja próximo, ou talvez dentro, da região experimental. O delineamento pode ser aumentado com pontos experimentais em novas coordenadas para que um modelo com termos quadráticos seja ajustadado aos dados. É comum aumentar do delineamento \(2^k\) para \(3^k\) ou usar o delineamento composto central. Estes serão vistos nos próximos capítulos.
Os códigos a seguir explicitam os cálculos para obter a estimativa pura da variância do erro, a estimativa do parâmetro de falta de ajuste e a soma de quadrados correspondente.
# Estimativa pura da variância do erro.
anova(m0)["Residuals", "Mean Sq"]## [1] 0.0004333333s2 <- var(da$y[da$lof == 1])
s2## [1] 0.0004333333# Médias dos pontos fatoriais e centrais.
m <- with(da, tapply(y, lof, mean))
# Diferença entre as médias é o termo de falta de ajuste.
c(m, diff = unname(diff(m)))## 0 1 diff
## 0.71625 0.95500 0.23875coef(m0)["lof"]## lof
## 0.23875# Soma de quadrados de `lof`.
n <- with(da, tapply(lof, lof, length))
sq_lof <- prod(n) * coef(m0)["lof"]^2/sum(n)
sq_lof## lof
## 0.182405# Estatística F do quadro de anova.
sq_lof/s2## lof
## 420.93465.4 Taxa de filtragem
Um produto químico é produzido em um vaso de pressão. Um experimento fatorial é realizado na planta piloto para estudar os fatores que podem influenciar a taxa de filtração deste produto. Os quatro fatores são temperatura (A), pressão (B), concentração de formaldeído (C) e taxa de agitação (D). Cada fator está presente em dois níveis. O engenheiro do processo está interessado em maximizar a taxa de filtragem.
A planilha eletrônica com os dados usados em MONTGOMERY (2012) está disponível para download no endereço http://bcs.wiley.com/he-bcs/Books?action=resource&bcsId=7009&itemId=1118146921&resourceId=26715&chapterId=75851. Os dados no fragmento de código abaixo estão na guia “Chapter 06” com nome “Problem 23”. Eles correspondem ao exercício 6-33 que usam os dados do exemplo 6.2.
Dataset disponível em https://gitlab.c3sl.ufpr.br/walmes/ce074/blob/master/scripts/book_example_hw_dataset.xlsx, aba “Chapter 06” com nome “Problem 33”.
O código abaixo cria o objeto com os dados no ambiente R e constrói gráficos para exame dos mesmos.
txt <- "Temperature Pressure Concentration Stirring Rate Filtration Rate
-1 -1 -1 -1 45
1 -1 -1 -1 71
-1 1 -1 -1 48
1 1 -1 -1 65
-1 -1 1 -1 68
1 -1 1 -1 60
-1 1 1 -1 80
1 1 1 -1 65
-1 -1 -1 1 43
1 -1 -1 1 100
-1 1 -1 1 45
1 1 -1 1 104
-1 -1 1 1 75
1 -1 1 1 86
-1 1 1 1 70
1 1 1 1 96
0 0 0 0 73
0 0 0 0 75
0 0 0 0 71
0 0 0 0 69
0 0 0 0 76"
da <- read.table(textConnection(txt),
header = TRUE, sep = "\t", dec = ",")
str(da)## 'data.frame': 21 obs. of 5 variables:
## $ Temperature : int -1 1 -1 1 -1 1 -1 1 -1 1 ...
## $ Pressure : int -1 -1 1 1 -1 -1 1 1 -1 -1 ...
## $ Concentration : int -1 -1 -1 -1 1 1 1 1 -1 -1 ...
## $ Stirring.Rate : int -1 -1 -1 -1 -1 -1 -1 -1 1 1 ...
## $ Filtration.Rate: int 45 71 48 65 68 60 80 65 43 100 ...da %>%
gather("fator", "valor", 1:4) %>%
ggplot(mapping = aes(x = valor, y = Filtration.Rate)) +
facet_wrap(facets = ~fator) +
geom_point() +
stat_summary(mapping = aes(group = 1),
color = 1,
geom = "line",
fun.y = "mean")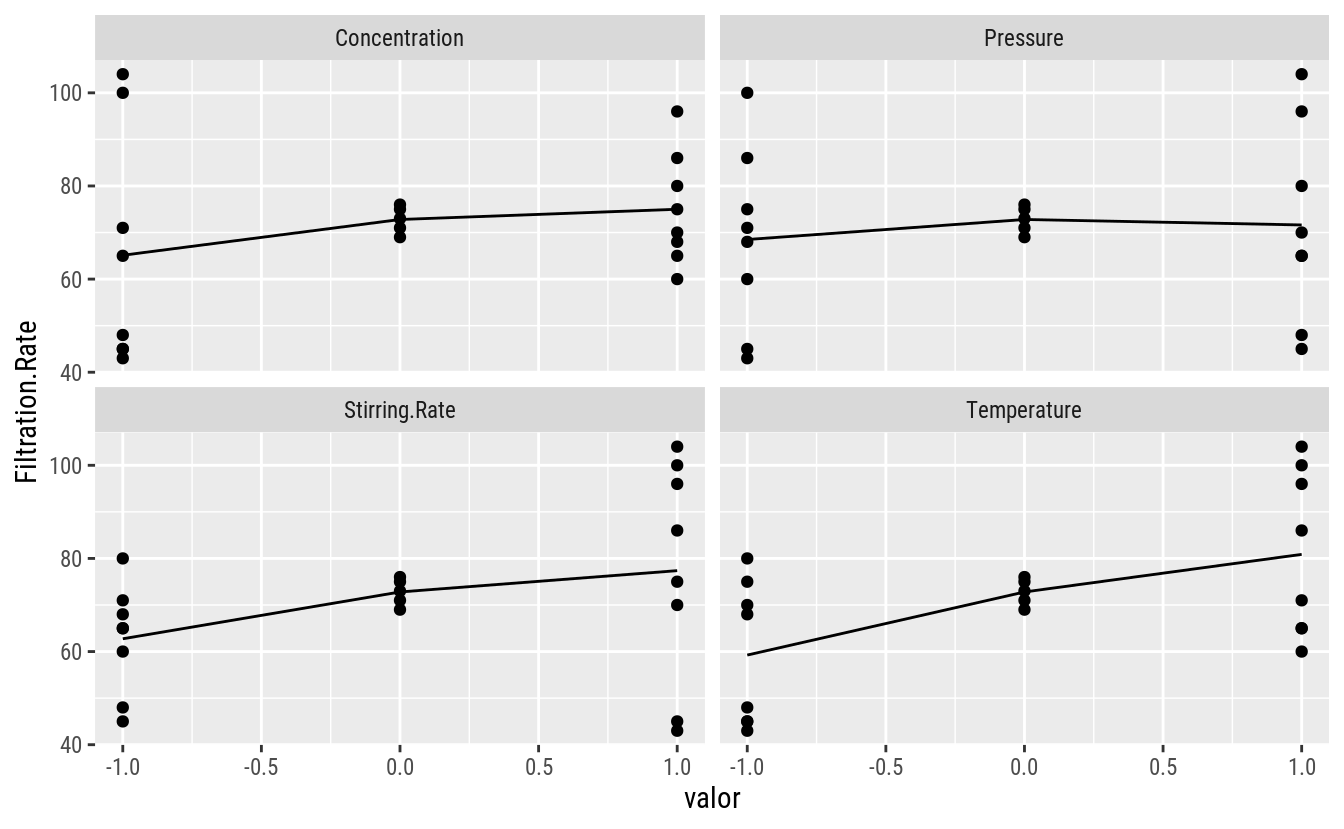
names(da) <- c(LETTERS[1:4], "y")
da$lof <- as.integer(da$A == 0)A avaliação dos gráficos indica haver pouca evidência para a rejeuitar a hipótese nula de curvatura zero. Portanto, ao que parece, o efeito dos fatores é linear na resposta na atual região experimental.
O código abaixo declara o modelo, estima os efeitos e exibe o quadro de análise de variância.
# Ajuste do modelo com pontos centrais.
m0 <- lm(y ~ A * B * C * D + lof,
data = da)
anova(m0)## Analysis of Variance Table
##
## Response: y
## Df Sum Sq Mean Sq F value Pr(>F)
## A 1 1870.56 1870.56 228.1174 0.0001120 ***
## B 1 39.06 39.06 4.7637 0.0944702 .
## C 1 390.06 390.06 47.5686 0.0023172 **
## D 1 855.56 855.56 104.3369 0.0005176 ***
## lof 1 28.55 28.55 3.4815 0.1354761
## A:B 1 0.06 0.06 0.0076 0.9346259
## A:C 1 1314.06 1314.06 160.2515 0.0002242 ***
## B:C 1 22.56 22.56 2.7515 0.1725007
## A:D 1 1105.56 1105.56 134.8247 0.0003144 ***
## B:D 1 0.56 0.56 0.0686 0.8063241
## C:D 1 5.06 5.06 0.6174 0.4759552
## A:B:C 1 14.06 14.06 1.7149 0.2604979
## A:B:D 1 68.06 68.06 8.3003 0.0449667 *
## A:C:D 1 10.56 10.56 1.2881 0.3197937
## B:C:D 1 27.56 27.56 3.3613 0.1406747
## A:B:C:D 1 7.56 7.56 0.9223 0.3912666
## Residuals 4 32.80 8.20
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Pela estatística F do quadro de análise de variância, não evidências para rejeitar a hipótese de que a curvatura é zero, ou seja, não rejeita-se a hipótese de que o modelo linear no efeito dos fatores é adequado na atual região experimental.
Os códigos a seguir explicitam os cálculos para obter a estimativa pura da variância do erro, a estimativa do parâmetro de falta de ajuste e a soma de quadrados correspondente.
# Estimativa pura da variância do erro.
anova(m0)["Residuals", "Mean Sq"]## [1] 8.2s2 <- var(da$y[da$lof == 1])
s2## [1] 8.2# Médias dos pontos fatoriais e centrais.
m <- with(da, tapply(y, lof, mean))
# Diferença entre as médias é o termo de falta de ajuste.
c(m, diff = unname(diff(m)))## 0 1 diff
## 70.0625 72.8000 2.7375coef(m0)["lof"]## lof
## 2.7375# Soma de quadrados de `lof`.
n <- with(da, tapply(lof, lof, length))
sq_lof <- prod(n) * coef(m0)["lof"]^2/sum(n)
sq_lof## lof
## 28.54821# Estatística F do quadro de anova.
sq_lof/s2## lof
## 3.48149Pelo exame completo do quadro de anova, verifica-se que o modelo poder ser simplificado. Sendo conservador, o modelo pode contemplar apenas as interações duplas AC e AD, não havendo razão forte para menter o fator B. Dessa forma, o código abaixo contém o modelo reduzido indicado.
# Simplifica o modelo.
m1 <- update(m0, . ~ A * (C + D))
anova(m1)## Analysis of Variance Table
##
## Response: y
## Df Sum Sq Mean Sq F value Pr(>F)
## A 1 1870.56 1870.56 109.401 2.758e-08 ***
## C 1 390.06 390.06 22.813 0.000245 ***
## D 1 855.56 855.56 50.038 3.786e-06 ***
## A:C 1 1314.06 1314.06 76.854 2.741e-07 ***
## A:D 1 1105.56 1105.56 64.659 8.084e-07 ***
## Residuals 15 256.47 17.10
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# Comparação entre modelos encaixados.
anova(m0, m1)## Analysis of Variance Table
##
## Model 1: y ~ A * B * C * D + lof
## Model 2: y ~ A + C + D + A:C + A:D
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 4 32.80
## 2 15 256.47 -11 -223.67 2.4797 0.1975Para detalhar o efeito dos fatores na resposta, serão feitos gráficos. Por haver mais sentido prático, será estudado o fator A (temperatura) e C (concentração) fixando níveis de D (taxa de agitação).
# Malha fina de valores para predição.
pred <- expand.grid(A = seq(-1, 1, by = 0.1),
C = seq(-1, 1, by = 0.1),
D = seq(-1, 1, by = 0.5),
KEEP.OUT.ATTRS = FALSE)
pred <- cbind(pred,
as.data.frame(predict(m1,
newdata = pred,
se.fit = TRUE)[1:2]))
# Gráfico da superfície média (valores ajustados).
ggplot(data = pred,
mapping = aes(x = A, y = C, z = fit, fill = fit)) +
facet_wrap(facets = ~D) +
geom_tile() +
scale_fill_distiller(palette = "Spectral",
direction = 1) +
geom_contour(color = "black") +
coord_equal()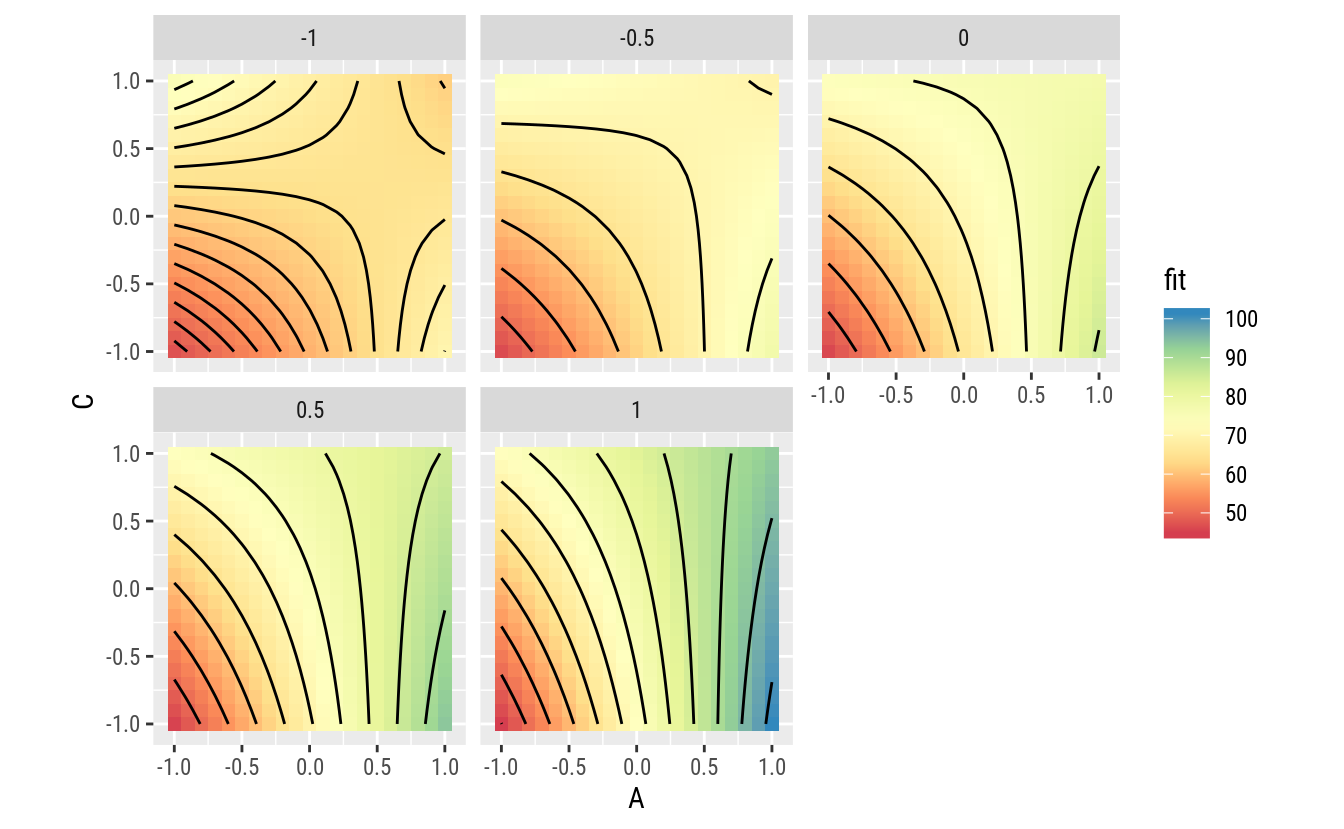
A função apresenta um comportamento que, conforme antecipado, indica que o efeito de A depende do valor de C e vice versa. É possível entender melhor com gráfico de linhas.
# Gráficos de linhas.
ggplot(data = pred,
mapping = aes(x = A, y = fit, color = C, group = C)) +
facet_wrap(facets = ~D) +
geom_line() +
scale_color_distiller(palette = "PRGn")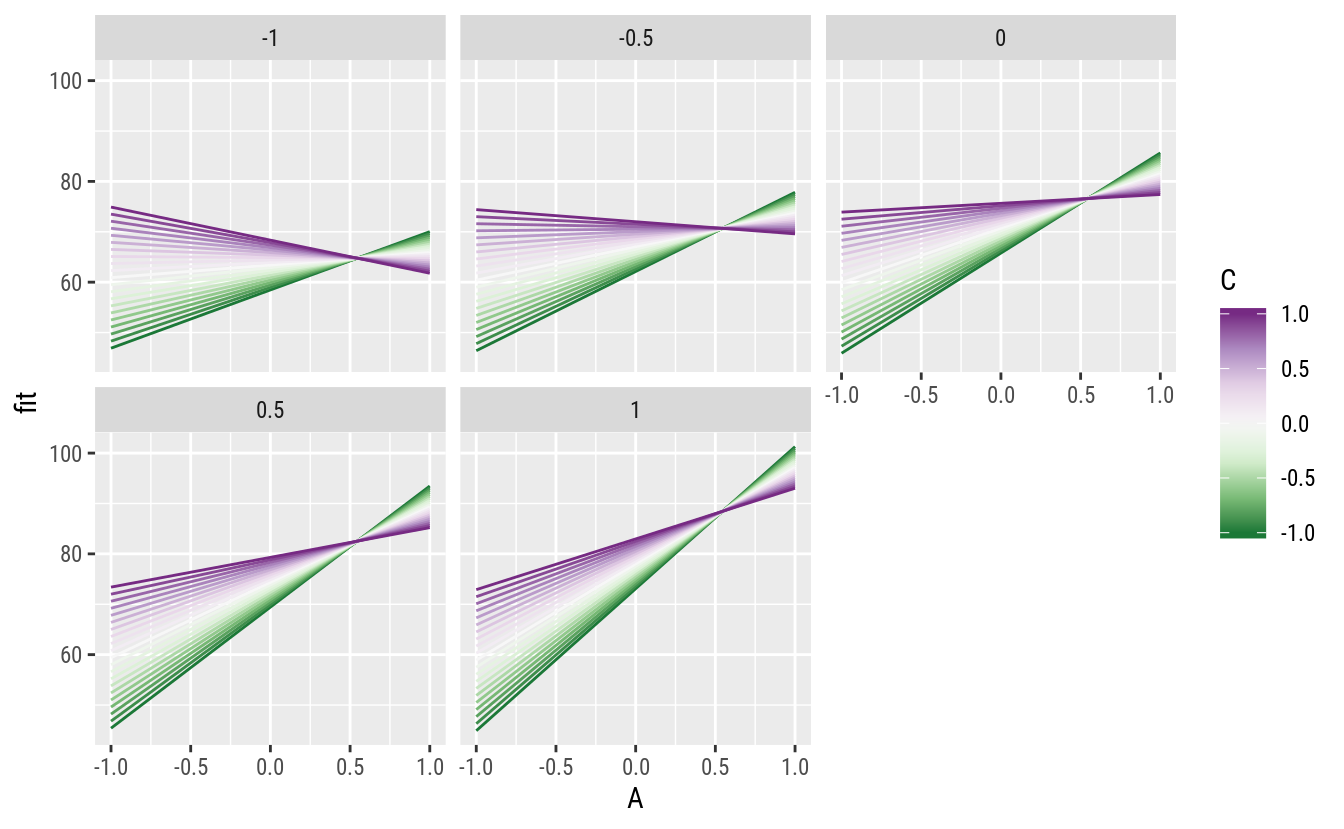
No fragmento a seguir são feitos gráficos de superfície para dar uma perspectiva diferente sobre a relação entre as variáveis.
# Esquema de cores para o gráfico com a `lattice`.
colr <- RColorBrewer::brewer.pal(11, "Spectral")
colr <- colorRampPalette(colr, space = "rgb")
# Adicionando os contornos sobre a superfície. Requer funções externas.
source(paste0("https://raw.githubusercontent.com/walmes/wzRfun/",
"master/R/panel.3d.contour.R"))
# Gráfico de superfície em 3D com isolinhas (ainda não recomendo).
wireframe(fit ~ A + C | factor(D),
data = pred,
as.table = TRUE,
drape = TRUE,
col = rgb(0, 0, 0, 0.25),
panel.3d.wireframe = panel.3d.contour,
col.contour = 1,
type = "on",
col.regions = colr(100))
# Valores preditos em cada ponto experimental.
grid <- unique(da[, c("A", "C", "D")])
grid$fit <- predict(m1, newdata = grid)
arrange(grid, fit)## A C D fit
## 1 -1 -1 1 44.90179
## 2 -1 -1 -1 46.90179
## 3 1 1 -1 61.77679
## 4 1 -1 -1 70.02679
## 5 0 0 0 70.71429
## 6 -1 1 1 72.90179
## 7 -1 1 -1 74.90179
## 8 1 1 1 93.02679
## 9 1 -1 1 101.276795.5 Exercícios
5.5.1 Problema 37
A planilha eletrônica com os dados usados em MONTGOMERY (2012) está disponível para download no endereço http://bcs.wiley.com/he-bcs/Books?action=resource&bcsId=7009&itemId=1118146921&resourceId=26715&chapterId=75851. Os dados no fragmento de código abaixo estão na guia “Chapter 06” com nome “Problem 37” pois correspondem ao exercício 6-37, página 301.
A resistividade em uma pastilha de silício é influenciada por vários fatores. Os resultados de uma experimento fatorial \(2^4\) realizada durante uma etapa crítica do processamento são mostrados na criada no bloco de código a seguir.
- Especifique e ajuste o modelo aos dados. Que conclusões podem ser tiradas sobre a curvatura?
- Estime os efeitos dos fatores. Plote as estimativas de efeito em um gráfico de probabilidade normal e selecione um modelo experimental.
- Analise os resíduos. Existe alguma indicação de inadequação do modelo?
- Repita a análise das partes anteriores usando ln(y) como a variável de resposta. Há alguma indicação de que a transformação tenha sido útil?
txt <- "A B C D Resistivity
-1 -1 -1 -1 1,92
1 -1 -1 -1 11,28
-1 1 -1 -1 1,09
1 1 -1 -1 5,75
-1 -1 1 -1 2,13
1 -1 1 -1 9,53
-1 1 1 -1 1,03
1 1 1 -1 5,35
-1 -1 -1 1 1,6
1 -1 -1 1 11,73
-1 1 -1 1 1,16
1 1 -1 1 4,68
-1 -1 1 1 2,16
1 -1 1 1 9,11
-1 1 1 1 1,07
1 1 1 1 5,3
0 0 0 0 8,15
0 0 0 0 7,63
0 0 0 0 8,95
0 0 0 0 6,48"
da <- read.table(textConnection(txt),
header = TRUE, sep = "\t", dec = ",")
str(da)5.5.2 Problema 41
A planilha eletrônica com os dados usados em MONTGOMERY (2012) está disponível para download no endereço http://bcs.wiley.com/he-bcs/Books?action=resource&bcsId=7009&itemId=1118146921&resourceId=26715&chapterId=75851. Os dados no fragmento de código abaixo estão na guia “Chapter 06” com nome “Problem 41” pois correspondem ao exercício 6-41, página 302.
Um artigo do Journal of Chemical Technology and Biotechnology (Response Surface Optimization of the Critical Media Components for the Production of Surfactin, 1997, Vol. 68, pp. 263–270) descreve o uso de um experimento projetado para maximizar a produção de surfactina. Uma parte dos dados desta experiência é mostrada no fragmento de código a seguir. A surfactina foi testada por um método indireto, que envolve a medição das tensões superficiais das amostras de caldo diluído. As concentrações relativas de surfactina foram determinadas diluindo em série o caldo até que a concentração crítica de micelas (CMC) fosse atingida. A diluição na qual a tensão superficial começa a subir abruptamente foi indicada pelo CMC-1 e foi considerada proporcional à quantidade de surfactante presente na amostra original.
- Analise os dados deste experimento. Identifique os fatores e interações significativos.
- Existe alguma indicação de curvatura na função de resposta? São necessárias experimentos adicionais? O que você recomendaria fazer agora?
- Analise os resíduos desse experimento. Existem indícios de inadequação do modelo ou violações das premissas?
- Quais condições otimizariam a produção de surfactina?
txt <- "Glucose NH4NO3 FeSO4 MnSO4 y
20 2 6 4 23
60 2 6 4 15
20 6 6 4 16
60 6 6 4 18
20 2 30 4 25
60 2 30 4 16
20 6 30 4 17
60 6 30 4 26
20 2 6 20 28
60 2 6 20 16
20 6 6 20 18
60 6 6 20 21
20 2 30 20 36
60 2 30 20 24
20 6 30 20 33
60 6 30 20 34
40 4 18 12 35
40 4 18 12 35
40 4 18 12 35
40 4 18 12 36
40 4 18 12 36
40 4 18 12 34"
da <- read.table(textConnection(txt),
header = TRUE, sep = "\t", dec = ",",
check.names = FALSE)
str(da)Referências Bibliográficas
MONTGOMERY, D. C. Design and analysis of experiments. 5th ed. New York: John Wiley & Sons, 2001.
MONTGOMERY, D. C. Design and analysis of experiments. 8th ed. New York: John Wiley & Sons, 2012.
MONTGOMERY, D. C.; RUNGER, G. C. Estatística aplicada e probabilidade para engenheiros. Rio de Janeiro: Livros Técnicos e Científicos, 2009.